HTML
When I already had laid out great plans for this research and had also begin to implement the required program, Google Inc. announced the results of their research: Web Authoring Statistics.
This is a great material, based on the data, gathered from over a billion (!) documents – a thousand times larger selection, than the one this survey is based on. I’d suggest anyone in interest of web standards and HTML in particular, to have a look at the results of that research.
As such a great research is available on the use of HTML elements and their attributes, I won’t repeat the information available from Google in here, although my program gathered the information about HTML elements and attributes. Instead I am going to focus on the data about (X)HTML pages, that the survey from Google doesn’t cover, like the document types and encodings most frequently used on web pages. But I start with the simplest thing measurable on HTML files – the size.
As figure 8 shows, most frequently the size of the web page is somewhere near 213 bytes (8KB). Most of the pages remain in range 29 bytes (0.5KB) to 216 bytes (64KB).

Figure 8. Frequency of different filesizes. Each column in location n shows how many pages are with filesize in range 2n to 2n+1.
But how big portion of the page is markup and how large is the real textual content of the page. Figure 9 shows clearly, that on most pages the markup-part dominates. An average page has something around 20% of text on a page. The figure shows a strong bias towards small percentage of text.
Of course, many of the URI-s in the used selection may have pointed to the front pages of sites, instead of real content pages, but this is just an assumption. Actually a lot of the pages pointed directly to the articles of some news sites. I’m quite sure, that this data is not the result of using this particular selection.

Figure 9. Distribution of pages based on the proportion of text in source code.
But what about comments? How much space do they consume? Apparently half of the pages (53%) don’t use comments at all (see figure 10). On those pages that use, the comments usually stay below 10% of the page size. Anyway, there doesn’t seem to be any good reasons to add extensive comments to HTML. Although adding comments to computer code is usually a good practice, this hardly applies to HTML. The weird pages are probably the ones appearing on the right side of the figure, which seem to be totally commented out.

Figure 10. Distribution of pages by the proportion of comments. The logarithmic scale is used, as only few pages have more than 10% of comments.
HTML elements
The following three figures are directly compareable to the ones found from the first chapter of research done by Google: Web Authoring Statistics – Pages and elements. Actually this is exactly why they are presented here – to provide a comparison with that study. I won’t cover the use of HTML elements in depth, because you can just head over to Google labs page and find a more accurate information from there.

Figure 11. Distribution of pages by the total number of (X)HTML elements used. When you compare it to the Google figure, you see, that the line is not that smooth, reflecting the great difference in the size of used selections.

Figure 12. Distribution by the number of different elements per page. Again the drawing from Google shows a lot smoother line; lot more similar to the normal distribution.
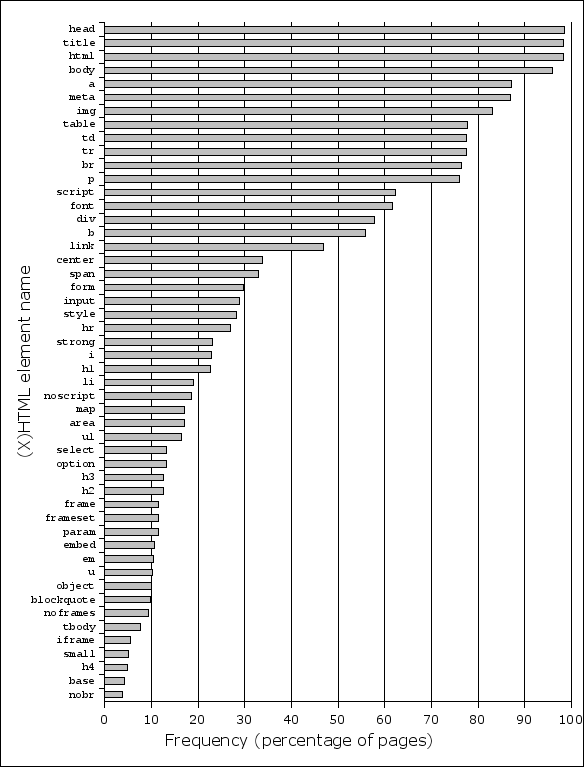
Figure 13.
Usage frequency of different (X)HTML elements.
On the figure from Google some elements have switched places,
but the differences aren’t significant and the general ordering of the
elements is the same. Sadly, Google only lists 19 most popular elements,
leaving you wonder: “Hey! But what about ul and h1
and many other important elements?” That’s why the figure above shows also
many of the less popular elements.
Document types
Only 39.08% of pages have a Document Type Declaration (DOCTYPE). 66.47% of pages with DOCTYPE only have the Formal Public Identifier (FPI) specified, lacking the System Identifier (SI – the URI pointing to the DTD).
The three overwhelmingly most popular DOCTYPEs are from the Transitional family: HTML 4.01, HTML 4.0 and XHTML 1.0. (Figure 14) The Transitional DOCTYPEs are so popular, that at the fourth place is a Transitional FPI, which is spelled incorrectly in lower case.
The pages, that use Strict doctype, mostly use the XHTML-one. But Strict is still less popular than Frameset and if you add together the HTML 3.2 and HTML 3.2 Final, then Strict is even less popular from those.
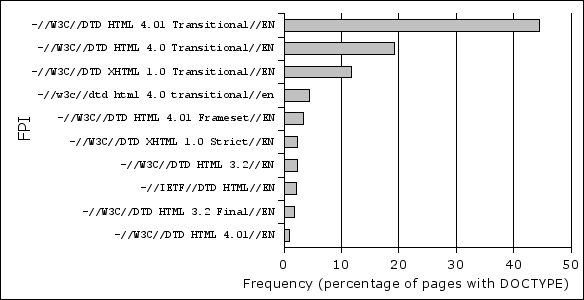
Figure 14. Most frequent FPI-s.
Based on the DOCTYPE comparison table built by Sivonen, and the gathered data about different DOCTYPEs usage, my calculations show, that roughly 90% of pages are rendered in Quirks mode (at least by IE 6). Even from the pages that specify DOCTYPE, 70% are rendered in Quirks mode.
XHTML
15.24% of pages with DOCTYPE specify some kind of XHTML DOCTYPE. Of those pages 22.40% use the XML prolog. (As a sidenote: 0,29% of HTML pages also includes the XML prolog.)
As W3C has recommended in Note about
XHTML Media Types,
XHTML documents should be served with application/xhtml+xml
Content-Type instead of the regular text/html. Only the XHTML
DOCTYPEs from XHTML 1.0 family may be served as text/html.
Only 0.24% of XHTML pages are served with the recommended DOCTYPE
(the number includes also few pages served with application/xml
or text/xml). Of course, the majority uses XHTML 1.0, where
this is permitted, but what about other XHTML DOCTYPEs?
Although only 4.46% of XHTML pages use some other DOCTYPE than XHTML 1.0, of those pages (that must be served as XHTML) only 2.80% are (in my selection 54 pages out of 1930).
The most frequent DOCTYPE served as application/xhtml+xml
was XHTML 1.1, followed by XHTML 1.0 Strict and Transitional.
Encodings
Only 66% of pages defines character encoding in one way or another. This means, that the remaining 34% uses Windows-1252 encoding, which is the default in most browsers.
Only 15% of all pages specify encoding in
HTTP header. Others
specify it with the meta element, if they do it at all. Of those
pages, that specify it in the HTTP header, 61% also specifies the encoding in
the meta element.
Windows-1252 is by far the most common encoding for web pages. Although figure 15 shows, that most pages specify ISO 8859-1 as their encoding, most of the browsers use Windows-1252 although the page says ISO 8859-1. Anyway – Windows-1252 is a superset of ISO 8859-1.
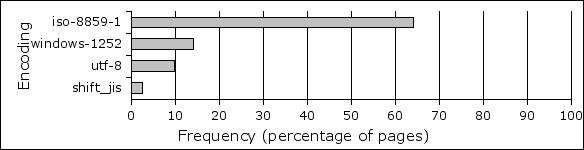
Figure 15. Distribution of pages by encoding (showing the percentages from pages that have encoding specified).
Multibyte encodings UTF-8 and Shift_JIS are also claming their place, but only UTF-8 seems to be something significant, nearing 10%. Many of the other encodings are given in the following figure 16.
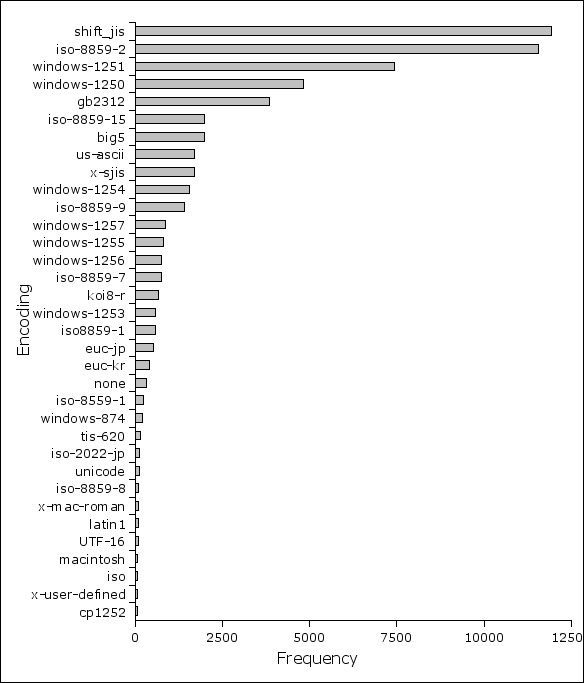
Figure 16. Less popular encodings. Continuation of figure 15.
Markup correctness
First of all I have to note, that 3.50% of pages were excluded from the valid-or-not statistics, because of the error message “unrecognized DOCTYPE; unable to check document”. This could have meant either an error in DOCTYPE or reference to custom DTD. Dagfinn Parnas, the author of the similar research in 2001, also removed the pages with this error from the analyzes.
I tried to keep as close to the beforementioned research, so I only excluded pages by the criteria, that Parnas did (although it has to be said that there definitely had to remain some small differences in the methodology). The result was, that out of 1,002,350 pages 25,890 or 2.58% were valid. At 2001 the result from Parnas was 0.71%.
I also used my more trimmed-down selection and calculated the percentage of valid pages from those. Out of 702,723 URI-s 18,373 or 2.61% were valid. Only 0.03% difference. So I think we can conclude, that roughly 2.6% of webpages referenced by Open Directory Project are valid. Probably this number also reflects quite well the situation of the web in whole - over 3 times better than 5 years ago (if we only talk about the percentage of valid pages).
The following figure 17 shows how many different error messages per page is most common. Figure 18 list the most common error messages by names which are given below in the text.
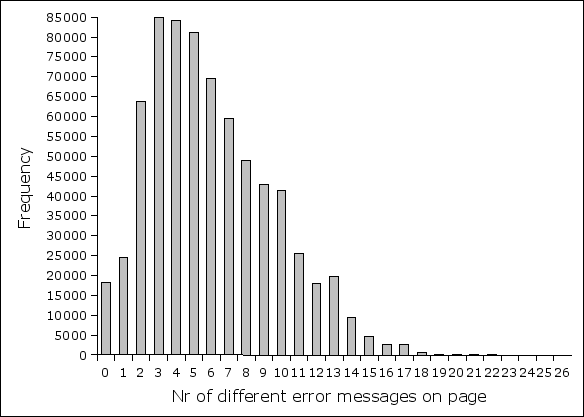
Figure 17. Distribution by the number of different error messages on page. The average number of errors is 6.02 and mean is 6.

Figure 18. Most frequent error messages.
- There is no attribute x for this element (in this HTML version).
- Required attribute x not specified.
- Missing document type declaration.
- End tag for element x which is not open; try removing the end tag or check for improper nesting of elements.
- Element x not allowed here; check which elements this element may be contained within.
- End tag for x omitted; possible causes include a missing end tag, improper nesting of elements, or use of an element where it is not allowed.
- Element x not allowed here; possible cause is an inline element containing a block-level element.
- Unknown entity x.
- Element x not defined in this HTML version.
- An attribute value must be quoted if it contains any character other than letters (A-Za-z), digits, hyphens, and periods; use quotes if in doubt.
- Value of attribute x cannot be y; must be one of a, b, c ... .
- Missing a required sub-element of x.
- x is not a member of a group specified for any attribute.
- Illegal character number x.
- Text is not allowed here; try wrapping the text in a more descriptive container.
- Duplicate specification of attribute x.
- Element x not allowed here; assuming missing y start-tag.
- Invalid comment declaration; check your comment syntax.
- Value of attribute x must be a single token.
- An attribute specification must start with a name or name token.
Kirjutatud 12. juunil 2006.